LinuxCentos7配置hadoop
准备条件
- apache-hadoop-3.3.0 jar包
hadoop-3.3.0(点击下载) - jdk1.8
jdk1.8(点击下载)
最好还是自己去官网下载然后上传到虚拟机,如果用下面的方式可以会有网速限制,毕竟自己的小服务器,带宽有限,或者点击下方两个连接进行下载,下载之后,最后把这个的名字改成和我的对应起来,这样下面的配置就方便了。
Hadoop3.0清华源
jdk1.8清华源
另外,需要准备三台虚拟机,分别命名为hadoop1,hadoop2,hadoop3,并且将这三台虚拟机这样配置接点,原理就不多说了。
| hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
开始配置
- 配置/etc/hostname,更改为hadoop1。目前这些步骤只用配置一台虚拟机,之后的通过虚拟机克隆得到haoop2,hadoop3。注意,在克隆之后,仍然要修改对应的主机名。
```swift
[root@localhost ~]# yum install vim -y
#先下载vim,方便编辑查看区别
[root@localhost ~]# vim /etc/hostname
```
将这里的这行删掉,然后修改成hadoop1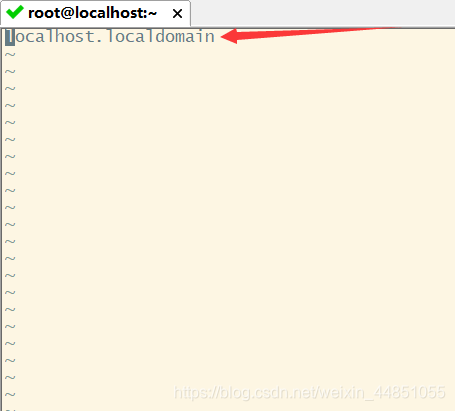
配置/etc/hosts
```swift
[root@localhost ~]# vim /etc/hosts
```
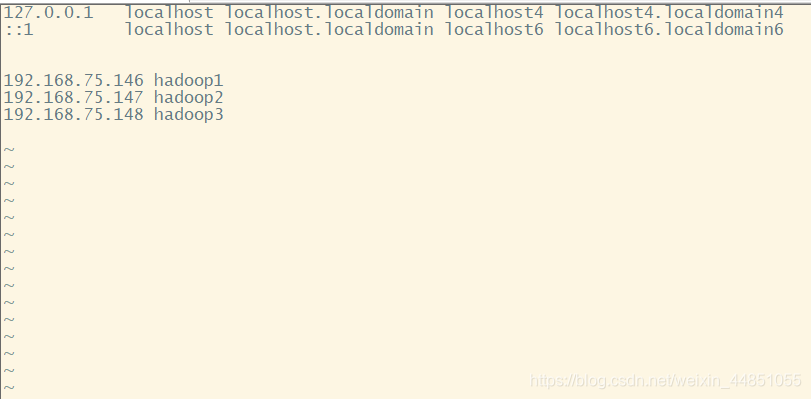
修改成这样,先填入另两个虚拟机的地址,因为是使用克隆,所以三台虚拟机之间的ip地址相差不过,只用小作修改。修改好以后重启一下虚拟机就生效了。配置jdk1.8
可以通过上面给的连接下载然后通过工具传到linux上面,或者使用下面这个命令下载jdk,跟着顺序来,一步步的来,别慌。
[root@hadoop1 ~]# yum install wget -y[root@hadoop1 ~]# mkdir /java [root@hadoop1 ~]# cd /java [root@hadoop1 java]# wget -i -c http://ljy0427.online/install/jdk1.8-linux.tar.gz #下载完成之后,解压 [root@hadoop1 java]# tar -zxvf jdk1.8-linux.tar.gz #解压成功之后,重命名文件夹 [root@hadoop1 java]# mv jdk1.8.0_144 java配置环境变量,在/etc/profile.d/目录下,自己创建一个.sh文件
[root@hadoop1 java]# vim /etc/profile.d/my_env.sh #添加如下东西export JAVA_HOME=/java/javaexport PATH=$PATH:$JAVA_HOME/bin
添加了以后,保存退出#重新刷新配置文件 [root@hadoop1 java]# source /etc/profile #测试配置成功,只要出现版本号就说明配置成功了 [root@hadoop1 java]# java -version配置hadoop
下载并解压apache-hadoop3.3.0
[root@hadoop1 java]# mkdir /opt/hadoop [root@hadoop1 java]# cd /opt/hadoop如果之前没有下载的话,就在这个/opt/hadoop使用下面这个命令下载吧。
[root@hadoop1 hadoop]# wget -i -c http://ljy0427.online/install/hadoop-3.3.0.tar.gz解压这个解压包
[root@hadoop1 hadoop]# tar -zxvf hadoop-3.3.0.tar.gz #重命名解压包 [root@hadoop1 hadoop]# mv hadoop-3.3.0 hadoop配置hadoop环境变量
[root@hadoop1 hadoop]# vim /etc/profile.d/my_env.sh添加如下内容
export HADOOP_HOME=/opt/hadoop/hadoopexport PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@hadoop1 hadoop]# source /etc/profile #测试配置是否成功 [root@hadoop1 hadoop]# hadoop #输入这个命令,看是否弹出一堆东西来
#之后先创建一些文件夹放着 [root@hadoop1 hadoop]# mkdir /opt/hadoop/hadoop_data [root@hadoop1 hadoop]# mkdir /opt/hadoop/hadoop_data/tmp [root@hadoop1 hadoop]# mkdir /opt/hadoop/hadoop_data/var [root@hadoop1 hadoop]# mkdir /opt/hadoop/hadoop_data/dfs [root@hadoop1 hadoop]# mkdir /opt/hadoop/hadoop_data/dfs/name [root@hadoop1 hadoop]# mkdir /opt/hadoop/hadoop_data/dfs/data- 关闭防火墙,参考下面这篇博文
关闭防火墙 - 关闭了防火墙之后,就可以克隆虚拟机了
在克隆之前,再来一个操作,内行人看了都直呼666的操作,看好了
创建一个脚本名字为,xsync,跟着我的顺序来,一步步的来,莫慌。
[root@hadoop1 hadoop]# mkdir /root/bin [root@hadoop1 hadoop]# cd /root/bin [root@hadoop1 bin]# vim xsync在里面添加如下脚本
#!/bin/bash if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #注意,如果你的主机名命名和我不一样,下面这三个更换成你的主机名 for host in hadoop1 hadoop2 hadoop3 do echo ================= $host ================= for file in $@ do if [ -e $file ] then pdir=$(cd -P $(dirname $file); pwd) fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done#创建完成之后,给这个脚本添加权限 [root@hadoop1 bin]# chmod +x xsync #可以克隆了,克隆的时候,一定要将虚拟机关机才可以。 #克隆完成之后,每台虚拟机都需要下载下面这个工具 [root@hadoop1 bin]# yum install rsync -y- 克隆完成之后,根据自己的虚拟机所分配的地址,修改三台虚拟机的/etc/hosts中的ip地址,以及/etc/hostname中的主机名
实现三台主机之间免密登录
参考我这篇博文
ssh免密登录
最好三台虚拟都使用ssh-copy-id hostname修改hadoop的配置文件
为了保证没啥大问题,在hadoop的hadoop-env.sh中添加JAVA_HOME的路劲
[root@hadoop1 ~]# cd /opt/hadoop/hadoop/etc/hadoop/ [root@hadoop1 hadoop]# vim hadoop-env.sh修改之前

修改之后
修改hdfs-site.xml
[root@hadoop1 hadoop]# vim hdfs-site.xml #如果你设置的主机名和我的不同,那记得将我这个配置文件里面的hadoop1替换成你对应的主机名。
在
<configuration>里面添加以下东西<!-- 指定NameNode的web端访问地址 --> <property> <name>dfs.namenode.http-address</name> <value>hadoop1:9870</value> </property> <!-- 设置SecondaryNameNode(2NN)的web端访问地址 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop3:9868</value> </property> <property> <name>dfs.name.dir</name> <value>/opt/hadoop/hadoop_data/dfs/name</value> <description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description> </property> <property> <name>dfs.data.dir</name> <value>/opt/hadoop/hadoop_data/dfs/data</value> <description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.permissions</name> <value>true</value> <description>need not permissions</description> </property>复制并且修改mapred-site.xml
[root@hadoop1 hadoop]# cp mapred-site.xml mapred-site.xml.template [root@hadoop1 hadoop]# vim mapred-site.xml也是一样的在
<configuration>里面添加以下东西
<!-- 指定MapReduce程序运行在Yarn上的地址 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hadoop1:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/opt/hadoop/hadoop_data/var</value>
</property>
配置yarn-site.xml,跟上面一样,在同样的位置添加以下东西
[root@hadoop1 hadoop]# vim yarn-site.xml<!-- 指定MapReduce走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop2</value> </property> <property> <description>The address of the applications manager interface in the RM.</description> <name>yarn.resourcemanager.address</name> <value>${yarn.resourcemanager.hostname}:8032</value> </property> <property> <description>The address of the scheduler interface.</description> <name>yarn.resourcemanager.scheduler.address</name> <value>${yarn.resourcemanager.hostname}:8030</value> </property> <property> <description>The http address of the RM web application.</description> <name>yarn.resourcemanager.webapp.address</name> <value>${yarn.resourcemanager.hostname}:8088</value> </property> <property> <description>The https adddress of the RM web application.</description> <name>yarn.resourcemanager.webapp.https.address</name> <value>${yarn.resourcemanager.hostname}:8090</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>${yarn.resourcemanager.hostname}:8031</value> </property> <property> <description>The address of the RM admin interface.</description> <name>yarn.resourcemanager.admin.address</name> <value>${yarn.resourcemanager.hostname}:8033</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value> <discription>每个节点可用内存,单位MB,默认8182MB</discription> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>配置core-site.xml,同上
[root@hadoop1 hadoop]# vim core-site.xml<property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/hadoop_data/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <!-- hadoop1的内网IP地址 --> <value>hdfs://hadoop1:9000</value> </property> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop1:8020</value> </property>配置workers,将三个主机名添加进去。
[root@hadoop1 hadoop]# vim workers记住必须严格按照我的效果图,主机名称后面不准有空格,只能换行!

同步这些配置文件到hadoop2,hadoop3上
到了这里,有些人已经崩溃了,还要配两次???
要配置两遍,那是对于别人,看好我的操作,一次就好。
前面不是创建了一个脚本xsync么?现在到它起作用的时候来了。看好了,别眨眼,记得直呼666。操作如下[root@hadoop1 hadoop]# cd .. [root@hadoop1 etc]# xsync hadoop/
怎么样,结果跟我这个一样不一样,你就看看另外两台虚拟机里面的这些对应的配置文件,是不是修改了,我就问你6不6,值不值得点个赞,加个关注??
再修改/sbin目录下的几个配置文件
[root@hadoop1 etc]# cd ../sbin [root@hadoop1 sbin]#修改start-dfs.sh,以及stop-dfs.sh,在这两个文件的开头加上以下配置
HDFS_DATANODE_USER=root HADOOP_SECURE_SECURE_USER=root HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
修改start-yarn.sh,以及stop-yarn.sh,在这两个文件的开头加上以下配置YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=root YARN_NODEMANAGER_USER=root
#又分发下已配置的配置文件到hadoop2,hadoop3 [root@hadoop1 sbin]# cd .. [root@hadoop1 hadoop]# xsync sbin/
启动Hadoop
初始化hadoop
[root@hadoop1 hadoop]# hadoop namenode -format
启动集群
[root@hadoop1 hadoop]# start-all.sh
然后再输入jps看看
[root@hadoop1 hadoop]# jps
只要运行结果如上,都说明成功了,那么现在去浏览器里面输入hadoop1这个主节点的ip地址访问试试,我的是http://192.168.75.146:9870/


这里表示存在三个节点,说明成功了,但是这里访问8088端口,却访问不了,这个时候就会有人认为又出问题了,其实没有。仔细回顾上面在一开始配置hadoop时,我弄了张表格,发现ResourceManager这个节点是配置hadoop2上面的。而这个东西,是要手动到hadoop2上面去运行的,才会出来。所以这个时候切换到hadoop2这台主机启动一下。hadoop2启动ResourceManager
[root@hadoop2 hadoop]# start-yarn.sh然后再使用jps查看一下
[root@hadoop2 hadoop]# jps
这不就成功了!!!然后再在浏览器里面输入hadoop2的主机地址,端口使用8088,看看效果吧,我的是http://192.168.75.142:8088/cluster

er
而且可以很清楚的在这里看到每台服务器的状态。


总结
可能也有其他教程,比我这个简单。但是我个人觉得,搭建一个hadoop就需要这样,使用三台服务器,一台当做NameNode,一台当做SecondaryNameNode,最后一台当做ResourceManager,这样三台服务器都担任着不同的角色,使得其他服务的负荷不重,能够尽量的保证整个hadoop的顺畅运行(个人观点,不喜勿喷)
